
When it comes to translation, Google Translate became a tool of everyday professional use perhaps for most of the people. Hence it is also a first choice that comes to my mind when looking for a service to use in a larger-scale application.
However, one quickly finds that there are actually many big corporate providers of translation APIs that support more than a hundred languages.
Providers of paid translation API vary in both quality and price.
In this article, I’ll share our experience in an overview of commercially-available translation services that you could possibly use in your app or service. Particularly, we’ll take a look at Google Translate, Amazon Translator and Microsoft Translator. Additionally, we compare these translation engines to the freely-available options: we’ll outline what you'll need to create a translation engine yourself to give you a glitch of what is possible if you decide to create a useful translation engine yourself.
We compare these translation engines to the freely-available options.
We’ll acknowledge both the benefits and drawbacks of keeping the translation engine in your hands, from the production perspective.
Modern machine translation: how do we translate in 2021
Before picking the right examples for comparison, let’s take a look at what kind of data modern translation systems use to model the translation from one language to another. Note that although this topic is super interesting from a Data Science perspective, if you came for the comparison of translation services, you don't need to bother about these technicalities.
The selection of the training data, just as the neural model architecture, that each of the services uses, is kept a secret by their providers. It’s also quite likely that some services use proprietary data sources that, for example, Google surely has available from their web crawls or other services. So what difference can it make, quality-wise?

Neural language models that are widely utilised nowadays by all the major translation services are first trained for a general language understanding of huge data sets of text, also referred to as corpus. The models learn to understand the text without any explicit training samples, on a task called Masked Language Modeling: here, the model is asked to correctly predict the best-fitting word in a given context. For those familiar with machine learning, I will be a bit more specific:
When training a model for Masked Language Modeling, the weights of the model are iteratively adjusted so that the probability of generating the expected masked word in a given context is maximized.
This is why only a large amount of tidy texts is needed for (pre-)training the language model (and a few months of computation time), without any costly collection of training samples by a human force.
Multilingual models are trained in the same way, with input and output vocabulary covering all input languages; over the time, the model learns to identify the language of the input itself, which is often easier than to guess the correct word into the context.
In addition to that, Machine Translation system is trained on a task of a conditional generation. This task is the same as Language Modeling, except that the already-generated words condition each following word. Again, if you are familiar with machine learning (but don't worry about it if you are not):
When training for Machine Translation, the weights of the model are iteratively adjusted so that the probability of generating the expected word in target text in a given source text and given already-generated words is maximized.

That is why Machine Translation requires large-sized parallel corpora which are datasets, that contain aligned sequences in both source language and target language.

Let’s translate!
Once the model is trained, the quality of the actual translation heavily depends on what kind of input text you translate and how well the model understands the domain. In order to get a meaningful and coherent translation of the text from an arbitrary domain, this domain should be somehow represented in the training data.
Neural machine translation models made a huge step towards generalization, ahead of their ancestor statistical translators, that, for example, Google Used until 2018. However, still, it's good to be aware that, for example, a translator trained solemnly on a domain of law discourses, such as ParaCrawl, will perform poorly in a medical domain, for example.
Aware of the available data sources and their domains, we’ve tried to evaluate the translation on as “harsh” examples as we could come up with.
We pick two samples from two rather diverse domains, one of the fairytales of Little Red Riding Hood story, with the rather unlikely sequential composition of the storyline and a meeting transcript, generated from the speech-to-text system, with its original flaws.
We also compare an output of our own translation model, that we have trained on freely-available data sources of OPUS, that uses the model that we’ll describe later.
In each of the translation outputs, we denote the factual flaws of each of the translation in bold; these are the parts of the output, that contain either misleading or wrong information, regarding the input.
After getting over the tedious registrations, you can try the translators yourself! Here are the links that we used to collect the translations: Google Translate, Amazon Translator, Microsoft Cognitive Translator, Gauss OPUS Translator.
Translation experiments
Note that we picked Czech-English pair for our evaluation, since Czech is one of the lower-resource languages supported by OPUS: we could find more training data, for example, for English-Spanish, or English-German, but for a minor language, the task gets more difficult for all translators.
Note that you can develop a translator of similar quality on any OPUS-covered language!

In the first experiment, we collect a snippet of The Little Red Riding Hood fairytale in one of OPUS's supported language: Czech, and evaluate the output in English, to allow you to compare.
1st Input text: Little Red Riding Hood in Czech:
“Žila jednou jedna hodná a milá dívenka. Všichni ji měli velice rádi a ze všech nejvíce maminka s babičkou. Babička jí ušila červený čepeček a podle něj jí začali říkat Červená Karkulka. Babička bydlela na samotě u lesa, kde široko daleko nebyla žádná jiná chaloupka. Babička se tam starala o lesní zvířátka. Jednou v létě maminka napekla bábovku, do košíku přidala láhev vína a řekla Karkulce: „Babička má dneska svátek. Vezmi košík a zanes ho k babičce do chaloupky. Ale jdi rovnou, ať se v lese nezatouláš!” Karkulka pokývala hlavou a zvesela se vydala na cestu. Cestu si zpříjemnila poskakováním a broukáním si.”

- Google Translate:
“There once lived a good and nice girl. Everyone loved her very much and mother and grandmother most of all. Grandmother sewed her a red cap and according to him they started calling her Little Red Riding Hood. Grandmother lived alone in a forest where there was no other cottage far and wide. Grandmother took care of the forest animals there. One summer, my mother baked a cake, added a bottle of wine to the basket, and said to Hood, “Grandma has a holiday today. Take the basket and take it to Grandma’s cottage. But go straight, so you don’t wander in the woods! “ Hood nodded and cheered merrily. She made her trip more enjoyable by bouncing and humming.” - Amazon Translator:
“There was one good and nice girl living once. Everyone liked her very much and most of all mum with grandmother. Grandma sewed her red beanie, and according to him they started calling her Little Red Riding Hood. Grandma lived secluded by the woods, where far and wide there was no other house. Grandma took care of the woodland critters there. One summer, Mum baked a candy, added a bottle of wine to her basket and told Riding Hood: “Grandma has a holiday today. Take the basket and take it to Grandma’s house. But go straight so you don’t stray in the woods! “The Riding Hood boiled his head and went on a journey. She made her journey more enjoyable by hopping and buzzing.” - Microsoft Cognitive Translator:
“There was a good, nice girl once. Everyone loved her very much and most of all mum and grandmother. Her grandmother made her a red hat, and according to him, they started calling her Little Red Riding Hood. My grandmother lived alone by the forest, where there was no other cottage far and wide. Grandma took care of the forest animals there. One summer, my mother baked a cake, added a bottle of wine to her basket, and told Little Red: “Grandma**’s having** a holiday today. Take the basket and take it to grandma’s cottage. But go straight so you don’t wander in the woods!” Little Red nodded her head and made her way cheerfully. She made her journey more pleasant by bouncing and humming.” - Gauss Translator (Trained on public OPUS):
“There was one good girl who lived there. They all loved her very much and most of them were mommy and grandmother made her a red hat and he said they started calling her Red Riding Hood. Grandma lived alone in the woods, where there was no other cottage nearby. Grandma took care of the forest animals there. One summer mommy baked a cake, added a bottle of wine to the basket and said to the Riding Hood: “Grandma has a holiday today. Take the basket and take it to her grandmother in the cottage. But go straight to the forest and don’t wander!” She nodded her head and hurried on her way. She made the journey more pleasant by bouncing and humming.“


2nd Input text: English transcript
In the second experiment, we translate the meeting transcript, originally written in English. We are aware that speech-to-text systems for English outperform the systems in other languages, hence the performance with transcripts in other languages would perhaps be more biased by the transcript quality.
Again, we denote the factual and misleading parts of translation by bold, discussed with the native speakers. You’ll have to believe us with this one if you do not speak Czech :)
“The tap project, led by former Secretary of Defense Ash Carter and on the West Coast by annual manual, is an effort to ensure that emerging technologies are both developed and managed in ways that protect humanity. Artificial intelligence is a foundational technology. That s court to many of the emerging technologies that we have tap, study and evaluate. Therefore, we re so pleased to be hosting today s of discussion with such a respected group of speakers from across the country who will introduce shortly. Today s discussion will address the following questions. What are the existing principles guiding the development and use of AI? What are the current gaps in AI governance, and how do we ensure responsible innovation moving forward to give you agree with brief overview of today s event? We ll hear briefly from Secretary Carter providing opening remarks, then Joey Ito, director of the M I T Media lab. Then we ll break into a fireside chat with several experts in the field, enclosed with an open Q and a session before I turn it over.”

- Google Translate:
“Projekt tap, vedený bývalým ministrem obrany Ashem Carterem a každoročním manuálem na západním pobřeží, je snahou zajistit, aby vznikající technologie byly vyvíjeny a řízeny způsoby, které chrání lidstvo. Umělá inteligence je základní technologie. To je soud pro mnoho nově vznikajících technologií, které využíváme, studujeme a hodnotíme. Proto nás velmi těší, že dnes provádíme diskusi s tak respektovanou skupinou řečníků z celé země, kteří se brzy představí. Dnešní diskuse se bude zabývat následujícími otázkami. Jaké jsou stávající principy, kterými se řídí vývoj a používání AI? Jaké jsou současné mezery ve správě AI a jak zajistíme, aby se odpovědné inovace pohybovaly kupředu a poskytly vám souhlas s krátkým přehledem dnešní události? Krátce uslyšíme od tajemníka Cartera úvodní poznámky, poté Joey Ito, ředitel laboratoře M I T Media. Pak se vloupáme do krbu s několika odborníky v oboru, uzavřeným otevřeným Q a relací, než to otočím.“ - Amazon Translator:
“Projekt kohoutku pod vedením bývalého ministra obrany Ashe Cartera a každoroční příručky na západním pobřeží je snahou zajistit, aby vznikající technologie byly vyvíjeny a řízeny způsobem, který chrání lidstvo. Umělá inteligence je základní technologie. To je soud mnoha vznikajících technologií, které máme kohoutek, studovat a hodnotit. Proto jsme rádi, že jsme hostitelem dnešní diskuse s takovou respektovanou skupinou řečníků z celé země, kteří brzy představí. Dnešní diskuse se bude zabývat následujícími otázkami. Jaké jsou stávající zásady, které řídí vývoj a používání umělé inteligence? Jaké jsou současné mezery ve správě umělé inteligence a jak zajistíme, aby odpovědné inovace pokročily, abychom vám poskytli souhlas se stručným přehledem dnešní události? Krátce uslyšíme od ministra Carterové, který předává úvodní poznámky, pak Joey Ito, ředitel laboratoře M I T Media. Pak se vloupneme do chatu u krbu s několika odborníky v terénu, uzavřený s otevřeným Q a relací, než ho otočím.“ - Microsoft Cognitive Translator:
“Projekt kohoutku, vedený bývalým ministrem obrany Ashem Carterem a na západním pobřeží každoroční příručkou, je snahou zajistit, aby nově vznikající technologie byly vyvíjeny a řízeny způsobem, který chrání lidstvo. Umělá inteligence je základní technologie. To je soud pro mnoho nově vznikajících technologií, které máme kohoutek, studium a hodnocení. Proto jsme tak rádi, že budeme hostit dnešní diskusi s tak respektovanou skupinou řečníků z celé země, kteří se brzy představí. Dnešní rozprava se bude zabývat následujícími otázkami. Jaké jsou stávající zásady, kterými se řídí vývoj a používání aiti? Jaké jsou současné nedostatky ve správě ai a jak zajistíme, aby se odpovědné inovace posunuly kupředu, abychom vám poskytli stručný přehled dnešního s. Krátce uslyšíme od tajemníka Cartera, který poskytl úvodní poznámky, pak Joeyho Ita, ředitele laboratoře M I T Media. Pak se vloupáme do rozhovoru u krbu s několika odborníky v terénu, uzavřený s otevřeným Q a zasedání, než jsem se obrátit.“ - Gauss Translator (Trained on public OPUS):
“Projekt stepování, vedený bývalým ministrem obrany Ash Carterem a na západním pobřeží každoroční příručkou, je snahou zajistit, aby nové technologie byly vyvíjeny a řízeny způsobem, který ochrání lidstvo. Umělá inteligence je základní technologie. To je soud pro mnoho nově vznikajících technologií, které máme klepnout, studovat a hodnotit. Proto jsme velmi potěšeni, že dnes pořádáme diskusi s takto respektovanou skupinou řečníků z celé země, kteří brzy představí. Dnešní diskuse se bude zabývat následujícími otázkami: Jaké jsou stávající zásady, které vedou k rozvoji a používání umělé inteligence? Jaké jsou současné mezery ve správě AI a jak zajistíme odpovědné inovace vpřed, abychom souhlasili s stručným přehledem dnešní události. Krátce se dozvíme od tajemníka Cartera, který předkládá úvodní poznámky, pak Joeyho Ita, ředitele laboratoře MIT Media. Pak se vloupáme do krbového chatu s několika odborníky v terénu, uzavřeného otevřeným Q a sezením, než ho otočím.“
Qualitative conclusions
We counted a number of errors and misleading parts to get a clue on what is the qualitative difference of the translators. A number of factual and misleading errors is quite similar in the fairytale case (3, 4, 2, 4), while slightly favourable to Google and Amazon in the second (6, 5, 9, 8). A speed of inference of a 5-sentence block of text is 2–3 seconds in all cases. Looking at each of the errors, they are rather of a similar type, among the translators. In the case of Riding Hood, translations struggle with correct pronouns and the misleading parts are mainly in the wrong adjectives. In case of the meeting transcript, the error resides mainly in the ambiguity of some English expressions, that are not properly resolved, perhaps due to the irregular context.
It seems that the differences in output quality are not so significant and the message of the output is understandable at all cases, although with some effort. This happens, if the domain of the input gets more "unconventional".
We did not find any significant differences in speed, although this could differ when using in a large-scale, over the API.
What does it cost?
Prices for translation APIs are usually billed for a number of characters of input. Some services, such as Microsoft’s, provide discounted bundles for larger volumes of translation. Hence, the comparison table shows the best achievable price for a given number of chars. To use more than 1 billion characters per month, Amazon and Google say they can provide individual pricing on demand.
Amazon and Microsoft allow to train your custom translator model on your own data, but it comes for an extra price and quality of such an approach is initially unknown. You would necessarily need to test the quality of translation after the training yourself, and quite likely, you would need to repeat the training multiple times to achieve your desired quality improvement on your data domain.
How much does the custom training cost? In case of Microsoft, a custom translation splits down to extra max $300 for training a model and then $40 per million chars, instead of the original $10. With larger volumes (over 62.5M chars), custom model pricing gets more complicated. With Amazon, this is projected to a price of the translation, that costs $60.00 per million chars, instead of the original $15. You would need to cover the computational resources needed for training on the cloud, but we have not found a more precise description of the process and pricing.
In the table below, we collect pricing for standard, general translation, as of February 2021. In general, custom translations are 1.8–4 times higher.
References (as of February 2021): Microsoft, Amazon, Google.

As you see, the price of translation varies significantly, even though the translation quality seems to be quite comparable.
Here are some examples with volumes of characters, that we estimated based on our own translation deployments:
- Multilingual chat support service: allows the customers to communicate in their mother language: a service request message contains ~100–200 characters. The whole conversation usually contains ~1200 characters in average, so if you have, say, 10k chat support requests per month, and you do not use a translator in any other service, it would monthly cost you $180 on Amazon, $120 on Microsoft, or $240 on Google Translate. This application is not as critical for translation quality, as some others, hence it is worth consider cutting down some costs on using cheaper translator, that still does the job. Importantly, the translation must be performed real-time, but this did not seem to be the problem in our tests: all translators were able to retrieve the response in 3 seconds, single-sentence texts usually took only ~1sec.
- E-shop localization: If you want to extend your customer base to other countries, it is a good start to localize your products description to native languages. We found that product descriptions on e-shops range between 3000–4000 characters, mainly depending on the price. So say you have an e-shop offering 5k products, that you want to localize into another language. Additionally, your goods providers update the description of the product once per 3 months. This would monthly cost you $100 on Amazon, $67 on Microsoft, or $133 on Google Translate.
Deploy your own translator
Clearly, utilising standalone translator might have some cost-saving benefits, especially once you aim to utilise translation in a real-time application, such as chat service, or large-volume application, for example, for office document processing. Neural translation service can be deployed on your own hardware, or into the cloud platform, such as AWS, just like any other application. Here’s a short review of performance scalability.
Let’s see what the resource consumption you need to count on is. Based on this, you should be able to estimate the expenses of your own use-case and deployment type.
Deployment of a service utilising base Transformer architecture that we used for translating aforementioned examples consumes 2164 MB of RAM with a single language pair, with additional 1274 MB for each language pair. Roughly the same is the requirement of memory on Graphical RAM of GPUs, that is significantly faster in inference, as you can see in the table below.

Train your own translator
If you are familiar with training neural networks, you could manage to train your own translation model and productise it, for example, like API, or simply as Python application. Note that, not only “language translation” is something you can train your translator to do. Similarly, you can train your model to generate summarization, such as the one on the video below, or essentially any other task, where both input and output are a textual sequence with known language domain.
With the same approach as with translation, you can train other interesting applications, such as news summarization.
But let's focus on translation for now. Here, we’ll share our framework on how to go around training your own translator, although the approach might vary depending on your language and text-domain specificity.
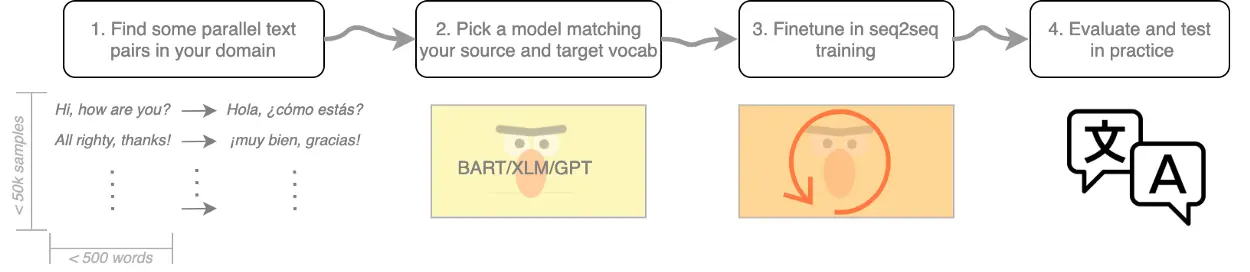
- Find some parallel data sequences. OPUS is a good starting point, but it contains some biases that are hard to eliminate without using additional data sets. For example, in our experience, Czech target sequences were relatively short, which caused the model to omit some parts of longer input sequences on translation.
- Pick a pre-trained model. Transformer model is a way to go if you’d like to get your translation to a quality comparable to cloud services. Use HuggingFace library to provide you with the base model for your desired source language and a lovely, convenient interface for training sequence-to-sequence models. Search for the models that are good at generating text, such as BART. Ensure that your model's source and target vocabulary covers the source and target languages you are interested in. That should be the case for mutlilingual models, as XLM, BART and others.
- Train your model. Once you've picked the model with input and output vocabulary covering your source and target language, go ahead and train your model on sequence-to-sequence generation. This is not yet too much of a beaten path, but there are examples of how to train a custom seq2seq model. A reliable evaluation of your translator's quality is a tricky task itself, mainly because a good performance on a single data set does not imply that the system performs similarly well on any input. Transformer models love to seek for heuristic shortcuts, such as the target shortening. We have seen this problem, for example, with OPUS training data for Czech to English. Similar problems can be partially avoided if you include at least two datasets to your validation monitoring. If the two are domain-orthogonal enough, the training BLEU will keep increasing and loss decreasing, while it already starts to degrade on an another-domain dataset. If your target language is data-limited and hence you can not use a distinct dataset for monitoring, create a small, artificial parallel corpus, that talks about something else than your training domain. Even as little as 50–100 sequence pairs will give you a good clue about how you’re doing outside your training data.
Image 5: BLEU of translation model on a held-out evaluation set, when fine-tuning to eliminate the bias of "shortening translations", mentioned above. Specific flaws of translation can be incrementally eliminated, once we can identify them, for example, by selecting a dataset subsample for fine-tuning. Here, we continue to iterate over the long training samples until BLEU score on held-out short translation pairs increase and we stop once it does not.
In this post, I hope to share with you an overview of the quality and pricing of the paid translation services.
I'm also hoping to demystify the use of complex NLP technologies, that are nowadays mainly held by a small number of monopolies. Thanks to the libraries like 🤗 HuggingFace, and thanks to people who stand behind open data sources like OPUS, we can continually democratize AI technologies and boost the research and development in previously closed domains!
If there's anything that comes to your mind, or if there's something you could use a bit of advice with, don't hesitate to leave a comment or message.
Ready to discover your next AI project?
Start today



.webp)

